
November 15, 2017 (Vol. 37, No. 20)
Andrew Anderson Vice President Advanced Chemistry Development
Graham A. A. McGibbon Ph.D. Director, Strategic Partnerships ACD/Labs
Sanjivanjit K Bhal Ph.D.
Cheminformatics Enables QbD Strategies for Process and Analytical Impurity Control
Over the past few years, global regulatory authorities have intensified their promulgation of quality-by-design (QbD) principles. QbD affords many important long-term benefits, not the least of which is “antifragility”: the ability to become more resilient and robust in the face of adversity.1 Attempts to implement QbD, however, can have a dramatic impact on product development groups and their supporting corporate informatics infrastructure.
This article will discuss how QbD requirements impact risk assessment, process assessment, material assessment, documentation, and traceability, and how these functions can be addressed using informatics software. One of the challenges in applying QbD principles in process development is establishing an acceptable Quality Target Product Profile (QTPP). This challenge may be met through:
- Evaluation of input Material Quality Attributes (MQAs)
- Evaluation of the quality impact of Critical Process Parameters (CPPs)
- Consolidated evaluation of every MQA and CPP for all input materials and unit operations
MQA assessment requires the careful consideration of input materials to ensure that their physical/(bio)chemical properties or characteristics are within appropriate limits, ranges, or distributions. Furthermore, for CPP assessment, unit operation process parameter ranges must be evaluated to determine the impact of parameter variability on product quality. The contribution of each unit operation in any pharmaceutical or biopharmaceutical manufacturing process—whether these operations are chemical (such as steps in a synthetic process) or physical (such as filtering, stirring, agitating, heating, chilling, or product formulation)—must be assessed.
Impurity control strategy development is an example of this iterative evaluation process (Figure 1). For regulatory submission of a substance or product under development, information from many activities is necessary to complete the quality module of a Common Technical Document (CTD or eCTD).

Figure 1. An iterative quality-by-design approach for controlling impurities in a biomanufacturing process.
Disparate Data Sources
Initially, chemical structure information may be available from chemists’ individual electronic laboratory notebooks (ELNs), but the affiliated unit operation details and the complete supporting molecular characterization data are not usually directly available. Some of this data and interpreted information may have been transcribed into spreadsheets within Microsoft Excel®—the system most widely used for managing process and impurity data.
In those Excel spreadsheets, synthetic process and supporting analytical and chromatographic data are abstracted to numbers, text, and images, and the raw data is stored in archives. Separate reports are often needed to assemble subsets of analytical characterization information and interpretations. The analytical information is transposed for decision-making purposes, but review of the decision-supporting data is, at best, impractical because it has been sequestered into different systems.
Batch-to-batch comparison data is also transcribed into Excel spreadsheets in an attempt to bring all the relevant information together into one system—unfortunately, one ill-suited to support rich chemical and scientific information. Project teams spend weeks on the assembly of this information for internal reporting and external submissions. This abstracted and repeatedly transcribed information is then reviewed to establish and implement control strategies in compliance with a QbD approach.
So, the challenge for product development project teams is to not only plan and conduct the process experiment’s unit operations, but to acquire, analyze, and then, (most important) assemble and interpret the various data from analysis of input materials and process information. Since the development process is iterative, all the salient data must be captured and dynamically consolidated as process operations are conducted to enable facile review of the information for ongoing risk assessment of impurities.
Concurrently, test-method development must demonstrate robust detection capabilities. That is, a test must be up to the task of generating a complete impurity profile, one that encompasses all significant impurities, known or suspected, from each process. Currently, control strategies rely on unrelated instruments and systems to acquire, analyze, and summarize impurity profile data and to record the interpretations made during process-route development and optimization.
A Comprehensive Approach
In order to establish effective process and analytical impurity control strategies, a comprehensive set of information must be collated. One of the biggest challenges is that the relevant types of information, data, and knowledge required exist in disparate systems and formats. These data include:
- Chemical or biological substance information (chemical structures or sequence information)
- Process information (unit operation conditions, materials used, location, equipment information, operator identification, suitable references to operating procedures and training, and calibration records)
- Unit-operation specific molecular composition characterization data (spectral and chromatographic data collected to identify and characterize compounds and mixtures, such as data from LC/MS, NMR, UV, and IR instrumentation)
- Composition differences in materials between specific unit operations and across all unit operations
- Comparative information for each batch for a single “process,” which is a single set of unit operations that are employed to produce a product or substance
- Comparative information for any or all employed processes.
Cross-functional development project teams, composed of representatives from the various groups and departments that generate the data and make decisions from it, spend many hours sourcing and assembling the necessary information. For each process iteration, effort is needed to acquire and evaluate new data, to analyze and interpret results, and to reassess the variance in impurity profiles for each process and across all processes.
One of the major challenges is that while spreadsheets tend to be quite effective for handling numbers and relating them in certain specified ways to calculate values such as sums and averages and make simple graphs, they are not very effective at handling and relating chemical structures with the analytical spectra and chromatograms used to identify them. Without a system that dynamically relates different kinds of input—chemical and analytical data, assessments of variance information, and the interpretative knowledge generated by computer algorithms and scientists—a tremendous number of full-time equivalent (FTE) days are spent just repeatedly searching for and compiling data, which presents a significant productivity challenge for project teams (Figure 2).
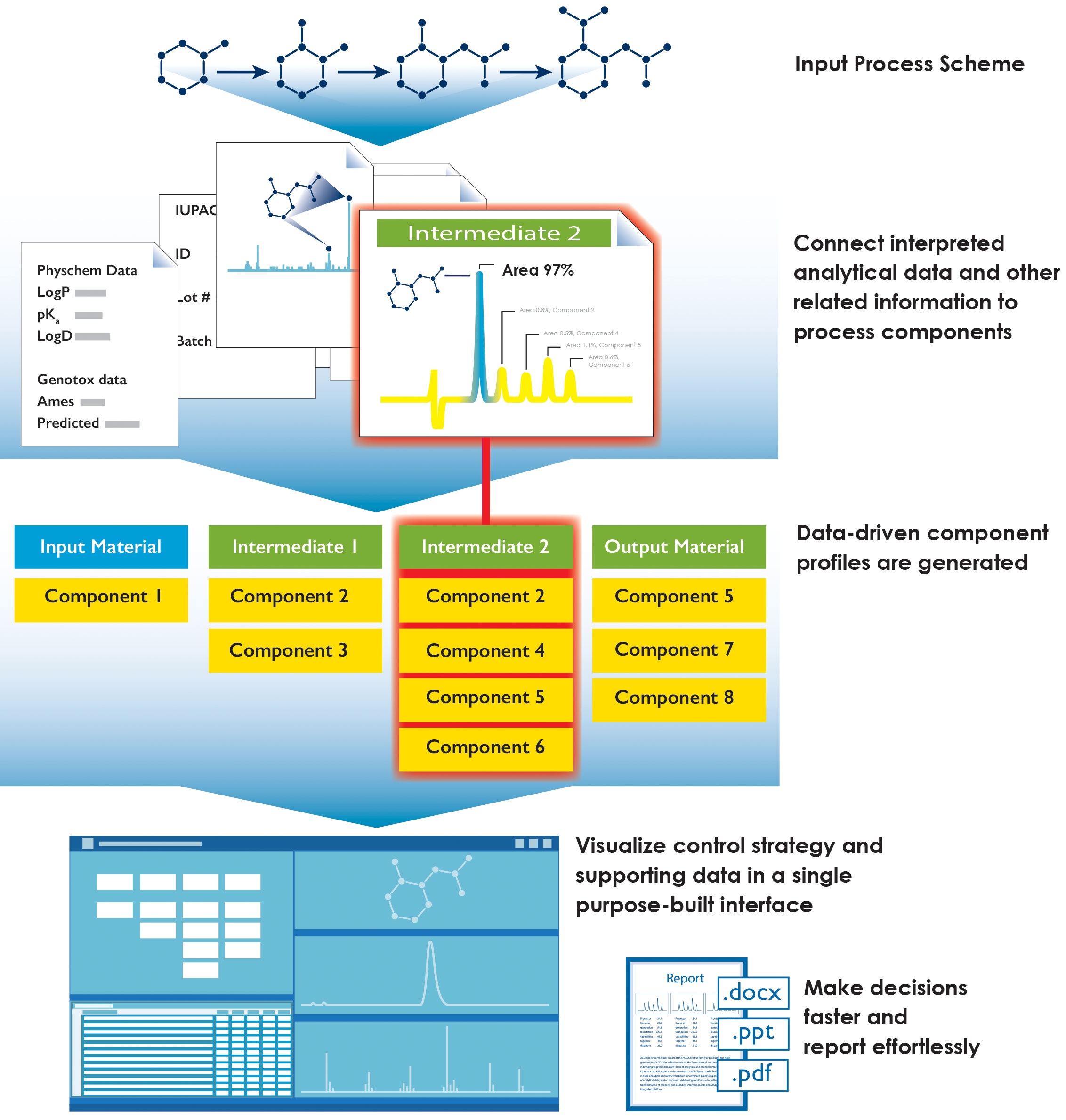
Figure 2. An idealized impurity management workflow.
An Integrated Platform
Users need the ability to simply aggregate all of the information, data, and knowledge in a single, integrated, and interoperable platform. Project teams must be able to search, review, and update the information on a continual basis as projects progress and evolve. Data access should support sharing of data for collaborative research while protecting data integrity.
Furthermore, from the perspective of preserving the rich scientific information therein, an ideal informatics system will also limit the need for data abstraction. While data abstraction serves a purpose—reduction of voluminous data to pieces of knowledge—it also brings limitations since important details, knowledge, and contextual information can be lost. In order to address all these challenges, a next-generation informatics infrastructure is required.
Discussions with development teams in the world’s largest R&D organizations revealed an unmet need in their ongoing struggles assembling and effectively managing process data. In response, Advanced Chemistry Development (ACD/Labs) created Luminata™. This informatics system, built on the ACD/Spectrus, a well-established multi-technique vendor-agnostic platform for analytical data management, addresses many of the challenges of effective process management for impurity control.
Luminata provides the ability to construct “process maps” enabling visual comparison of molecular composition across unit operations (Figure 3). The software allows the user to capture and associate the wide variety of related spectroscopic and chromatographic data in a single environment for each stage and substance.
The technology goes beyond simple data capture by storing the context of the experiment and the expert interpretation and decisions resulting from it. Dynamic visualization of this assembled, live (instantly re-useable), and aggregated information preserves data integrity while supporting quick and confident decision-making and making better use of highly talented individuals. Finally, Luminata makes possible the full review of project information, from batch to supporting data, in a single environment.
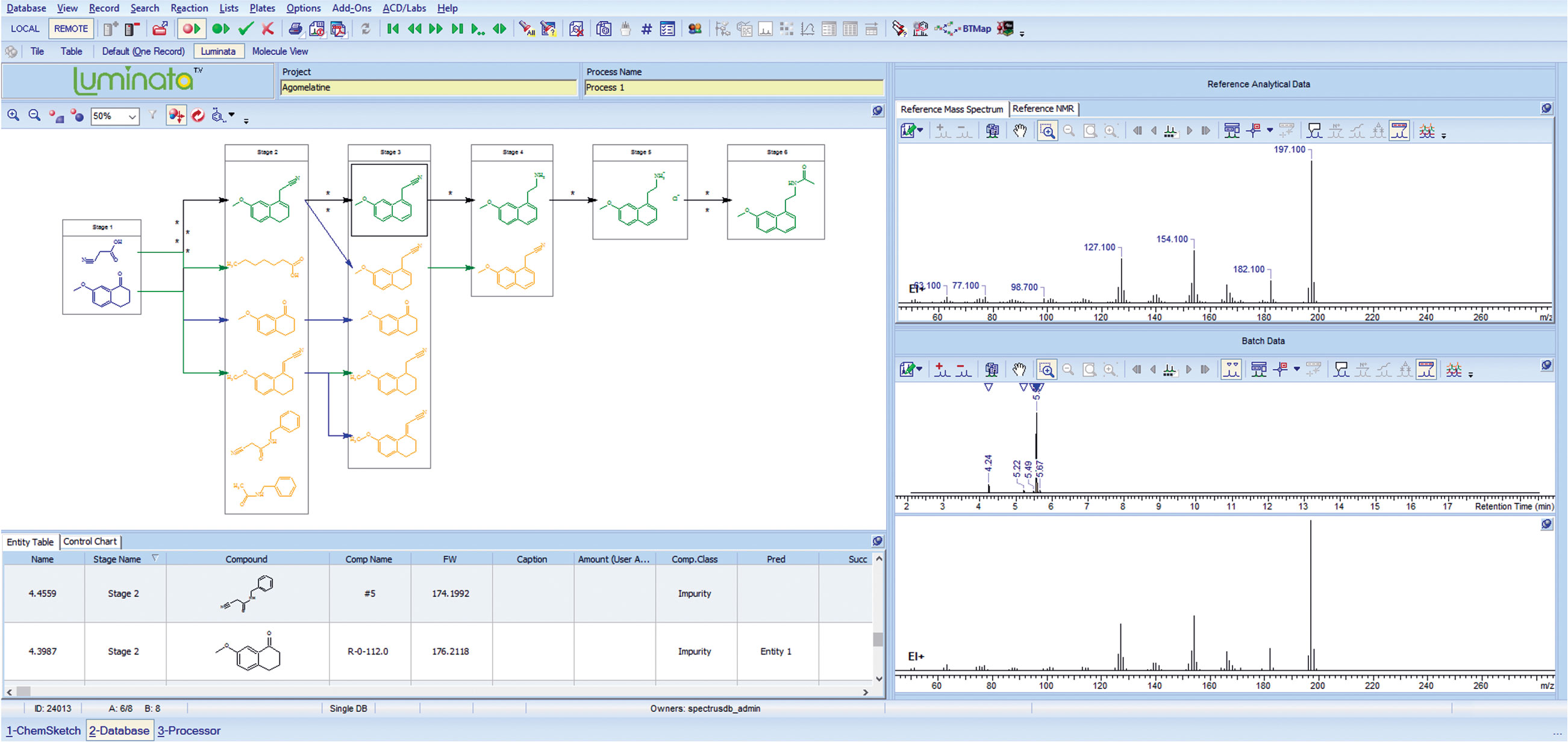
Figure 3. A screenshot from Luminata™, software for the management of impurity data.
Andrew Anderson is vice president of innovation and informatics strategy,
Graham A. McGibbon, Ph.D., is director of strategic partnerships, and Sanjivanjit K. Bhal, Ph.D., is director of marketing and communications at Advanced Chemistry Development (ACD/Labs).
Reference
1. N.N. Taleb, Antifragile: Things That Gain from Disorder, (Random House, New York, NY, 2012).

