
January 1, 2014 (Vol. 34, No. 1)
From our January 1, 2014 issue.
The heroic age of pharmaceutical development may be drawing to a close. Once, clinical boons such as the polio vaccine and angiotensin-converting enzyme inhibitors were the work of identifiable geniuses. But future advances may depend on vast data troves and machine-driven calculations as impersonal as they are tortuous. The last three decades have shown that the paramount medical challenges of our time, such as Alzheimer’s disease or cancer, are rife with intricacies that require comprehensive, multimodal studies.
In facing up to these challenges, pharmaceutical development is passing into the big data era, a time in which data collection occurs on a scale beyond human comprehension. Yet it is becoming apparent that merely collecting large volumes of data will not be enough. No big data approach is complete without a way to manage the vast amounts of information regarding products, patients, customers, prescriber behaviors, and clinical trials across hundreds of different types of compounds.
Such issues will be discussed at the “Big Data and Analytics in Life Sciences Forum,” an IQPC event scheduled to take place January 27–28 in Boston. Senior executives from giants in the research industry will present practical case studies from pharmaceutical powerhouses in all stages of the big data journey.
For instance, John Reynders, Ph.D, chief information officer of Moderna Therapeutics, says he will explain how even seemingly small challenges in big data are big in their own way. To Dr. Reynders, the obvious “big”—the process of massive data collection—is the easiest part of a bioinformatics approach. He is interested in the subtle considerations needed to conduct a big data project. These include tackling the complexity and heterogeneity of the collected information along with assembling the right team and tools for data mining and machine learning.
But above all, addressing these fundamental questions during the early days of the project is crucial to its success. “Like any aspect of engineering, the decisions that you make in the early stages can have profound impacts further on,” says Dr. Reynders.
Potential Pitfalls
One common pitfall is when labs expect data analytics to be “a silver bullet that will solve everything,” so they build a large, data-centric infrastructure without identifying in advance the right data tools and strategies for addressing the specific question that they are trying to answer.
“People will buy hardware-accelerated approaches for relationship searching, which is great if you have sequel-based queries, but maybe the problem actually required a more dynamic navigation of very non-obvious relationships in graphs or triple stores,” Dr. Reynders remarks. “Rather than bring the data to your application, it is better to bring the application to your data.”
Pharmaceuticals for Alzheimer’s disease, which he explored while working at Johnson and Johnson, represent a realm where all dimensions of big data came to life in trying to characterize which patients with mild cognitive impairment could ultimately develop full-blown dementia. The data may come from multiple modalities, such as MRI scans for hippocampal shrinkage, PET scans for amyloid-beta load, genetic markers (APOE or clusterin), and neuroinflammatory markers in the blood.
Much of this is plotted over a time course, adding another dimension to finding a signature that identifies those at risk for dementia.
“Without big data, you wouldn’t be able to even begin to tease apart those patient populations,” continues Dr. Reynders, who adds that solving the heterogeneity challenge is essential to assembling mRNA therapeutics at Moderna.
The company is developing large genetic algorithms, many of which will be executed on an Amazon cloud (S3 and glacier), to deal with mRNA codon optimization and experimental analysis to make sure therapeutics are reaching the right tissues or staying stable in certain environments.
New-Wave Tools For Big Data
Big data analysts are shedding their reputations for merely being the keepers of data stockpiles, and they are developing the next-generation data tools that guide research projects from their beginning, middle, and end stages.
At the IQPC forum, Kerstin Kleese van Dam, Ph.D, an associate division director at Pacific Northwest National Laboratory (PNNL), will describe her research on crafting new solutions to master the exponential growth in the volume, rate, and heterogeneity of informatics data. Dr. Kleese van Dam leads a group charged with data management for PNNL’s science and security instruments. These devices create tremendous quantities of information.
For instance, PNNL currently houses a dynamic transmission microscope that produces 1,000 images per day, but scientists at the national lab are building new models that will achieve 1,000 images per second within the next year or two, and a million images per second three years from now.
Rather than merely extract and organize the data, Dr. Kleese van Dam’s team is creating provenance tools that interpret the data throughout the research process.
“We need new computational processes that speed up this analysis and really figure out what is important in this wealth of data,” remarks Dr. Kleese van Dam.
The life science implications of this work range from streamlining OMICS data to measuring the rates of biochemical reactions to stress testing materials for implants or biomedical engineering.
“We are creating an environment where people can interact with large amounts of data but still pick out the nuances,” says Dr. Kleese van Dam. “Because the data is so complex, the researcher need data scientist to support them in this effort.”
Her talk will address three data paradigms utilized by her team: 1) always on analysis; 2) analysis in motion; and 3) analytics at the edge.

Kerstin Kleese van Dam, Ph.D., from PNNL researches scientific data management, curation, and exploitation, utilizing metadata and semantic technologies.
Always on analysis allows researchers who are collecting data from many different sensors, instruments, and modalities to create real-time correlations between the findings while the project is ongoing.
Analysis in motion takes this a step further. It not only checks the gathered information for answers to a priori hypotheses, it also tries to detect unexpected phenomena that may emerge.
“The models are looking for features in the data streams that researchers can already classify—stuff they would expect. The models also interpret patterns in outliers or unexplained findings,” comments Dr. Kleese van Dam. “The scientists can then change the course of the project if they want to explore unexpected experimental findings in much more detail by targeting a new area of interest.”
Analytics at the edge obviates the standard requirement of moving data from its source of origin to a central site of analysis. Aside from time and money constraints, the process is not very efficient.
“A classic approach is to pull data into one central point, integrate, and then run analyses over it. To a certain extent that works, but with the new data volumes, pulling petabytes from every location for integration and analysis is no longer always an option.”
Data-Driven Pharma Strategies
Informatics is also changing the face of the pharmaceutical business model. “Integrating a big data mindset into corporate business processes represents an evolution in how corporations think about their operations,” says Chris Waller, Ph.D, director of chemoinformatics at Merck, whose presentation will advise business line executives and data professionals on how to create a data-driven organization.
Making a point similar to that raised by Dr. Reynders, Dr. Waller said it is tempting to apply big data solutions to all problems given the relative glitz and glamour of these emerging technologies. The tactic, however, can create more harm than good.
“Not all data problems are big data problems. Force yourself to align the most appropriate technologies to the business problems for which you are designing solutions,” Dr. Waller advises. “I’ve seen instances where big data problems were artificially created through the aggregation of various disparate sources of data into big data repositories that required disaggregation in order to address non-big data use cases. Make your systems as complex as necessary to address your business needs, and no more.”
Dr. Waller also encourages the use of real-world evidence for pharmaceutical development and that data tactics adopted by Merck are used to demonstrate the value of their medicines and vaccines and develop the new options that further enhance patient health.
Metrics for Clinical Trials
Another company whose business strategy is steeped in real-world big data is Covance, one of the world’s largest drug development services companies. As a contract research organization (CRO), the company serves as a broker that helps pharmaceutical companies conduct clinical trials on emerging drugs.
Big data drives much of this enterprise, according to Dimitris Agrafiotis, Ph.D, vp and chief data officer at Covance. The company’s Xcellerate® approach to clinical design taps into a global network of clinicians to find those who recruit patients and collect biological samples or measurements most efficiently.
When a clinician sends a biological sample or lab test kit to Covance, it is assigned a unique identifier that provides a timestamp of that patient’s screening. Each timestamp represents a trail marker that can be used to track the patient’s journey through the clinical trial as well as the clinician’s efficiency toward completing the trial.
Covance uses data and quality metrics to track the historical performance of clinical investigators, which allows them to accurately forecast how clinicians will perform in a trial, according to Dr. Agrafiotis. This serves as a catalyst for designing faster and cheaper clinical trials.
“We know which investigators perform well, and we know which disease areas they perform well in,” Dr. Agrafiotis says of the company’s database, a composite spanning more than 115,000 investigator sites amassed while executing more than 3,600 clinical trial protocols in 95 countries over the last 25 years.
Their data algorithms create composite scores of each researcher based on factors like enrollment profile, the number of cancelled tests, and operational metrics, including did the investigator submit the data adequately and follow the proper standard operating procedures for the clinical trial.
In a recent analysis, they compared the performance of more than 2,000 industry protocols from 2008 to 2012 against with five randomly chosen Covance clients from the same timeframe. Industry trials took an average of 55 weeks to activate 80% of their investigator sites. According to Dr. Agrafiotis, Covance accomplished the same task in 30 weeks.
“If that’s a billion dollar molecule, it means a half a billion dollars in savings,” asserts Dr. Agrafiotis. “This has profound financial and regulatory implications toward pharmaceutical trials.”
In addition, the company’s at-home facilities are equipped with end-to-end lab capabilities, allowing them to cover the entire continuum of clinical trial design from late-stage discovery to exploring preclinical animal models to running tests on human samples, he explains.
Dr. Agrafiotis, who was previously vice-president of informatics at Johnson & Johnson, believes the pharmaceutical industry is at an inflection point, poised to undergo a large transition whereby CROs like Covance become the powerhouses of R&D.
“Pharma, in my opinion, will retain strategies, sales, and marketing, while everything else will done outside,” offers Dr. Agrafiotis. “As pharmas rely more on external vendors, I think discovery will be done mainly in biotech, and all clinical development and design will be done by CROs. The trend is so clear.”
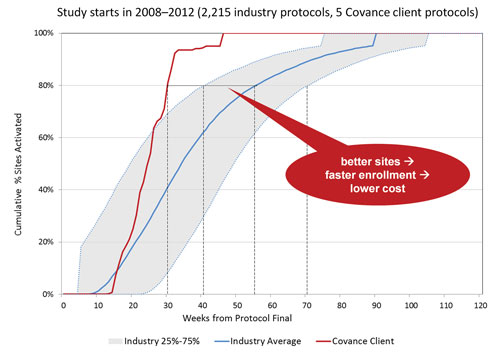
On average, clinical trials take an average of 55 weeks to activate 80% of investigator sites (solid blue line). By using Covance’s Xcellerate™ platform for site selection, a Covance client took only 30 weeks to achieve the same task (red line). This result shows the advantage of using historical performance data to guide clinical site selection.

